



GSoC 2023 Week 4 - Experiments? Yes. Results? No.
09 Jun 2023This blog post is related to my GSoC 2023 Project.
This week, I had mainly spent my time trying out various little experiments to see if any of them made a difference on performance. Even though I got no real results out of it, I was trying to get more accomodated with the codebase and I learned a lot from it!
I also spent time on issue #33910, and I was able to get the code to run 50% faster just with one word and one comma added!
Here are the various experiments that I tried:
-
Only insert nodes in
PruningListwhenuse_empty()inAddUsersToWorklistandAddToWorklistWithUsersMy first attempt was at building off of the work that I had done last week, where I introduced a new parameter
IsCandidateForPruningto reduce the number ofPruningListinsertions that were done. However, it seems like that patch already did pretty much all the work with regards to speeding up the pruning list, and I only saw a tiny improvement to performance, so small that I didn’t bother checking it on the compile time tracker.I still believe there is performance to be gained here, I just don’t know how much. I’m assuming its not a lot.
-
Change
DenseMapto useconstexprforshouldReverseIterateThis change was me taking a shot in the dark, just throwing things at the wall and trying to see if something stuck. In this case, I naively assumed that the compiler would somehow not be able to optimize one line of code whose values are known at compile time and all required function definitions are visible into an if statement.
As expected, this change did not net anything at all.
-
Change
DenseMapto use Fibonacci HashingThis one was a little silly, to be honest.
DenseMapcurrently uses quadratic probing to locate keys, and I wanted to try a different form of hashing to see the performance differences. Fibonacci Hashing is a form of hashing which seemed quite promising at first to me. However, I either implemented it incorrectly or quadratic probing is already good enough (I suspect it is the former), as I did not see any improvements when I used Fibonacci hashing, and infact the performance slightly regressed.One thing which made it quite difficult for me to test small changes properly was the fact that changing any part of that header would lead to recompiling pretty much every other file in the project. This is really quite offputting, but I’m still interested in this change and might come back to it later.
-
Disable the first call to
DAGCombiner(curiosity’s sake)This change was just for fun. I wanted to see what would happen if I diasbled one of the calls to
DAGCombiner::RuninSelectionDAG. As expected, it led to many test failures. -
Call
.insert()with range onSetand.clear()onVectorinSmallSet::insertThis was part of the changes I was making to try and make the
PruningListinDAGCombinerrun faster. I assumed that the set operations were slow (correct), but then I assumed thatSmallSetVectorusedSmallSet(wrong). It actually usesSmallDenseSet.I actually did expect this to make a difference though, no matter how minor. I assumed that calling the batch operations on
SetandVectorwould be faster (which they are), but I didn’t realize that these operations are only called once in the entire set’s lifetime, which is when it is expanding from the “small” to the “large” representation. :facepalm: -
Change
WorklistandPruningListsmall size to 128 inDAGCombinerThis was another silly change. I assumed that increasing the small size would lead to better performance, but I didn’t realize that the small size was in terms of number of elements, not in terms of number of bytes. So this actually led to my cache getting thrashed and my performance getting slashed, as the small representation uses a linear search, which is great at small sizes but awful with larger sizes.
-
Change
while (!CallSUnits.empty())to range-based for loop inBuildSchedUnitsThis loop is present at the end of the function
ScheduleDAGSDNodes::BuildSchedUnits. This is also a function that I see taking up a lot of time, so I thought that changing this from the usual worklist-style loop to a normal one would lead to some performance gain, but either I guessed wrong about how many times this part of the code executes or how much time the constituent computations actually take.It is probably a combination of both,
SmallVectoroperations are very cheap in the small representation and that loop is not run many times. The reason I know this is that changing the small size ofCallSUnitsdid not affect the runtime, and in fact led to a slight regression in performance.
To be honest, these experiments were really quite helpful to me. While quite demoralizing, they helped me better understand how the LLVM data structures work and also how to use KCacheGrind more properly in terms of analyzing the emitted machine code and the source code.
These experiments also helped me run an experiment which gave unexpectedly good results, this I will cover in the post for next week.
Regarding issue #33910, the reason for the isKeyOf operation being so slow was not because of the
ordering of the comparisons within it but instead because of the number of times it was called. I should have expected
that some &&s and ==s would not have had a meaningful difference on performance, and instead
it would’ve been a much better idea to reduce the number of times that function is called.
This was something I realized when I actually dove into the issue and measured the various equality operators and how
often they were inequal. This gave a very interesting result: the comparisons were pretty much dominated by
differences between the OffsetInBits metadata, and it was about 60x more likely to be inequal on average:
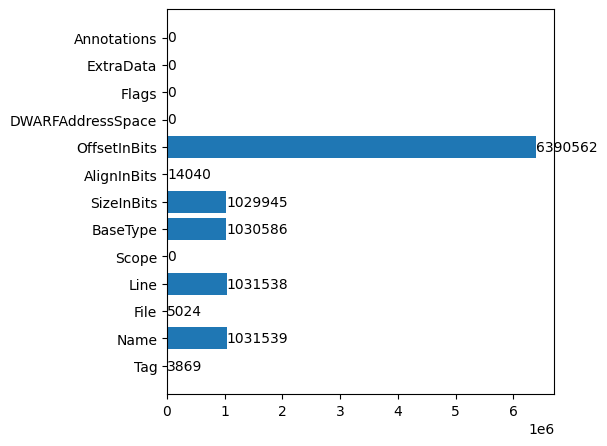
Note that this is not even the full data generated, I stopped it when it had roughly as many rows as there are
OffsetInBits inequalities, because at that point I had 1.2GiB of data and not enough RAM to load it all
at once.
When I brought this up with my mentor, they told me that this is probably the cause of the quadratic behaviour, as
the getHashValue function for DIDerivedType did not take into account the
OffsetInBits parameter. The reason for so many inequalities was because the file provided by the
issue (at least for the small case) has pretty much 20,000 lines of metadata with exactly two unique names:
Va and Vb, with only the OffsetInBits differing between them. This hit the
corner case of not including that value in the hash function, which caused an explosion in the collision chains and
thus caused the compile time explosion.
As expected, changing the hash function to take OffsetInBits into account led to a huge reduction in
compile time, from roughly 8 seconds to 4.3 seconds. This pretty much erased isKeyOf from the flamegraph,
and the only bottleneck now is ReplaceableMetadataImpl::replaceAllUsesWith, which requires uniquing all
metadata all over again each time it is called. This is extremely slow, and it makes sense to only unique things after
the whole file is parsed.
As per my GSoC proposal, I was actually supposed to work on this during the midterm eval, so I will be pushing fixing this issue back while I focus on non-edge cases. I think the solution is simple enough that postponing it will be fine.